storm 初步
介绍
storm 是分布式的流式计算框架,用于数据的实时计算场景。具有低延时,可扩展,数据不丢失等特性。
几个概念
Topology
一个 Topology 类似一个 mapreduce ,表示处理的逻辑。Topology 如果不显示的杀死会一直运行,即使集群重启后任务仍然存在。
Spouts
获取数据源的组件,接受外部数据然后转换为 topology 内部数据。spouts 可以是可靠的,缓存 tuple ,当消息处理失败时重新发送。也可以不缓存 tuple。
spouts 的关键方法是 nextTuple() 方法,storm 会循环调用这个方法。
ack(),fail() 用于保证可靠。Bolts
完成具体的处理逻辑,主要是 execute() 方法在起作用。
Stream groupings
- Shuffle grouping 随机分组
- Fields grouping 按字段分组,具有相同字段的保证分配到同一个bolt,但是不保证不同字段分配到不同 bolt
- Partial Key grouping 类似于 Fields grouping,但是有更好的并行度,能提高资源利用率
- All Grouping 所有的 bolt 接收同一个 tuple
- Global Grouping 所有的流指向 Bolt 的 Task ID 最小的 task
- None Grouping 等价于Shuffle grouping
- Direct Grouping 由Tupe的生产者来决定发送给下游的哪一个Bolt的Task
- Local or shuffle grouping 如果目标 bolt 有一个或多个 task 在同一个工作进程中,tuple 会随机发送给这些 task,否则其行为跟 shuffle grouping 一致
Tasks
每个 spout、bolt 对应多个 task ,每个 task 对应一个executor
Workers
每个 Worker 是一个 JVM 和他上面执行的所有 task,每个 JVM 会占用一个 slot
worker, executors and tasks 之间的关系
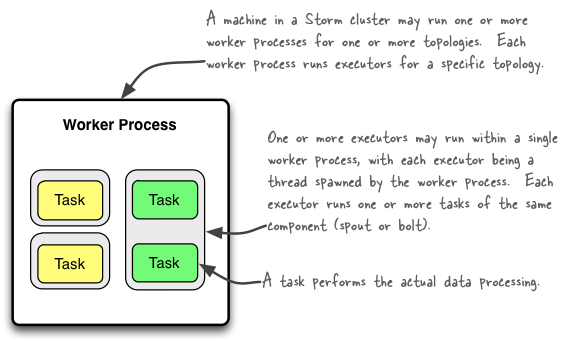
一个 worker 属于一个 topology,一个 worker 运行多个 executor
一个 executor 是 worker 的一个线程,其中可能运行一个或多个 task,一个 executor 中的 task 都是同一个 bolt 或者 spout。
task 执行实际的数据处理逻辑,默认 task 的数量等于 executor 也就是为每个 task 开启一个线程。
如果 task 数量不等于 executor 会出现多个 task 运行在一个 executor 中也就是一个线程中的情况。所以我们在实现 spout/bolt 时最好不要使线程阻塞。
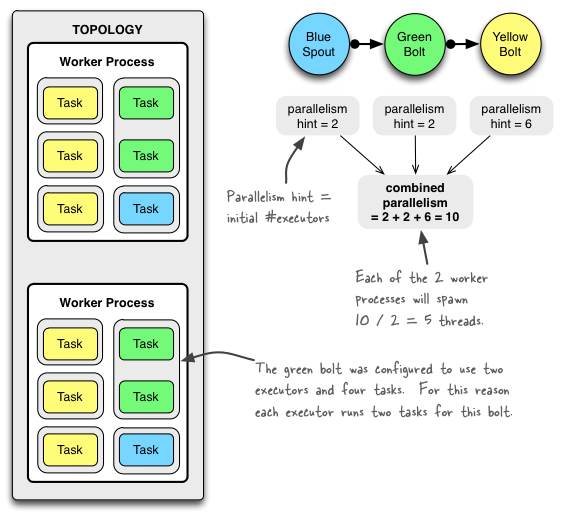
topology 例子
设置 topology 有2个 worker. blue-spout 并行度是2 ,green-bolt 有两个executor ,4个 task. yellow-bolt 有6 个 executor .
Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology(
"mytopology",
conf,
topologyBuilder.createTopology()
);
安装
配置 zookeeper 集群。配置 storm 环境变量
配置 storm-env.sh 中 JAVA_HOME
配置 conf/storm.yaml
storm.zookeeper.servers: - "acyouzi01" # 指定 Master 节点 nimbus.seeds: ["acyouzi01", "acyouzi02"] # 指定一个 supervisor 最大允许多少个 slot supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703启动
# 启动 nimbus storm nimbus # 启动 supervisor storm supervisor # 启动 ui, 监听在 8080 端口 storm ui ##http://{ui host}:8080.
相关命令
# 提交/杀死
storm jar topology-jar-path class
storm kill topology-name [-w wait-time-secs]
# 禁用/启用
storm deactivate topology-name
storm activate topology-name
# 重新设置并行度
storm rebalance topology-name [-w wait-time-secs] [-n new-num-workers] [-e component=parallelism]*
# 在 superviser 上运行,启动 drpc 服务
storm drpc
# 在 superviser 上运行,杀死上边的所有 worker
storm kill_workers
storm list简单使用(wordcount)
// spout
public class SimpleSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private String[] sentences = new String[]{
"This is a test sentencs",
"You gotta treat every day like a holiday",
"and I know life is gonna suck some days",
"That makes you feel so good when time are rough it is okay",
"and I know life is gonna suck some days but I can not complain"
};
private Random random;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
random = new Random();
}
@Override
public void nextTuple() {
collector.emit(new Values(sentences[random.nextInt(sentences.length)] ) );
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
}
// split
public class SplitBlot extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String sencence = input.getStringByField("sentence");
String[] words = sencence.split(" ");
for (String word : words){
word = word.trim();
word = word.toLowerCase();
if (!word.isEmpty()){
collector.emit(new Values(word));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
// counter
public class CountBolt extends BaseRichBolt {
private Map<String,Integer> counters = new HashMap<>();
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
@Override
public void execute(Tuple input) {
String word = input.getString(0);
if( counters.containsKey(word)){
counters.put(word,counters.get(word)+1 );
}else {
counters.put(word,1);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public void cleanup() {
System.out.println(counters.toString());
}
}
// topology
public class MyTopology {
public static void main(String[] args) throws InterruptedException {
Config config = new Config();
config.setNumWorkers(2);
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout",new SimpleSpout(),4);
builder.setBolt("split",new SplitBlot(),2).shuffleGrouping("spout");
builder.setBolt("count",new CountBolt(),6).fieldsGrouping("split",new Fields("word"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Test",config,builder.createTopology());
Thread.sleep(30000);
cluster.killTopology("Test");
cluster.shutdown();
}
}Storm Worker 通信
参考 http://www.michael-noll.com/blog/2013/06/21/understanding-storm-internal-message-buffers/
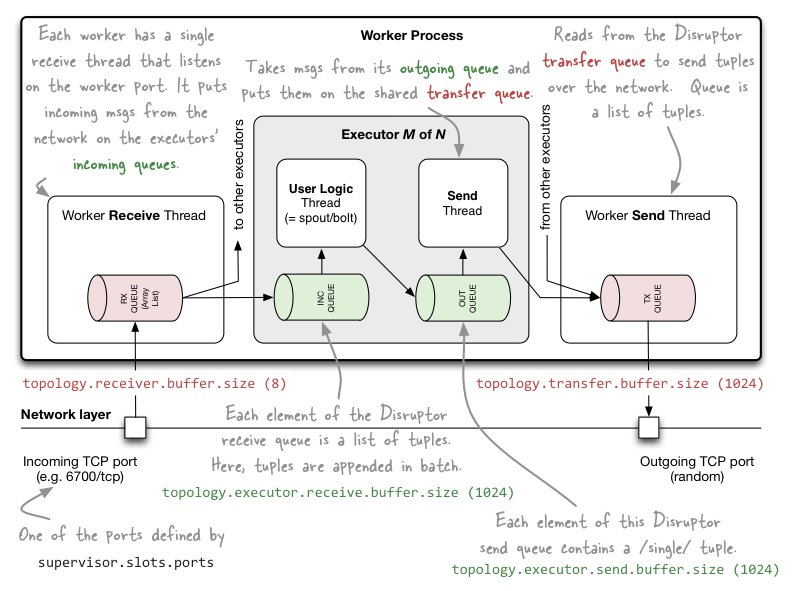
内部通信使用 Disruptor,外部通信基于 netty (0.9).
每个 worker 有独立的 接受和发送线程。
每个executor有自己的输入输出队列,Worker接收线程将收到的消息通过task编号传递给对应的executor(一个或多个)的输入队列。
ACK 机制
参考 http://blog.csdn.net/zhangzhebjut/article/details/38467145
storm 的 ack 机制是通过一个唯一的 spout-tuple-id 来跟踪一颗 topology 树,有键值对 <spout-tuple-id, ack-val> , 每次 spout/bolt 发送消息或调用ack(),fail()方法时发送一个 ack-val 到 acker(task),这个值与旧的 ack-val 做异或操作。当在 Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS 设定的时间内,如果最终 ack-val 为 0 说明消息被完全处理,否则说明消息处理失败。
acker 数量可以通过 Config.TOPOLOGY_ACKERS 设置,默认值是 1.
关闭 ack 机制的方法
第一是把Config.TOPOLOGY_ACKERS 设置成 0. 在这种情况下, storm会在spout发射一个tuple之后马上调用spout的ack方法。也就是说这个tuple树不会被跟踪。
第二个方法是在tuple层面去掉可靠性。 你可以在发射tuple的时候不指定messageid来达到不跟踪某个特定的spout tuple的目的。
最后一个方法是如果你对于一个tuple树里面的某一部分到底成不成功不是很关心,那么可以在发射这些tuple的时候unanchor它们。 这样这些tuple就不在tuple树里面, 也就不会被跟踪了。
ack 示例
// spout
public class AckSpout implements IRichSpout {
private SpoutOutputCollector collector;
private String[] mess = new String[]{
"test0",
"test1",
"test2",
"test3",
"test4",
"test5"
};
private Random random;
private Map<String,Values> buffer = new HashMap<>();
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
random = new Random();
}
@Override
public void nextTuple() {
Values values = new Values(mess[random.nextInt(mess.length)]);
String messageId = UUID.randomUUID().toString().replace("-", "");
collector.emit(values,messageId);
buffer.put(messageId,values);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public void ack(Object msgId) {
System.out.println("send success !!! -- " + msgId);
buffer.remove(msgId);
}
@Override
public void fail(Object msgId) {
System.out.println("send fail !!! -- " + msgId);
collector.emit(buffer.get(msgId),msgId);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("name"));
}
}
// bolt
public class AckBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
Object messageId = input.getMessageId();
String name = input.getStringByField("name");
if (name.equals("test0")){
collector.fail(input);
}else {
System.out.println(name);
collector.ack(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("name"));
}
}
// topology
public class AckTopology {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("ackspout",new AckSpout(),1);
builder.setBolt("ackbolt",new AckBolt(),2).shuffleGrouping("ackspout");
Config config = new Config();
config.setNumWorkers(1);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test-00",config,builder.createTopology());
}
}drpc
实现从远程调用storm集群的计算资源,而不需要连接到集群的某一个节点
参考 http://blackproof.iteye.com/blog/2221356
示例代码
参考 http://storm.apache.org/releases/1.0.2/Distributed-RPC.html